01
Analyze
We start with a thorough analysis of your current workflows to identify where AI can create the highest impact.
From data pipelines to AI agents, we design and deploy systems that save time, reduce costs, and scale operations.
We help companies move from AI experiments to production-ready systems.
01
We start with a thorough analysis of your current workflows to identify where AI can create the highest impact.
02
Then we craft custom AI systems for your company, continuously prioritizing quality and safety.
03
Then we run offline evaluation and observability to continuously improve your system.
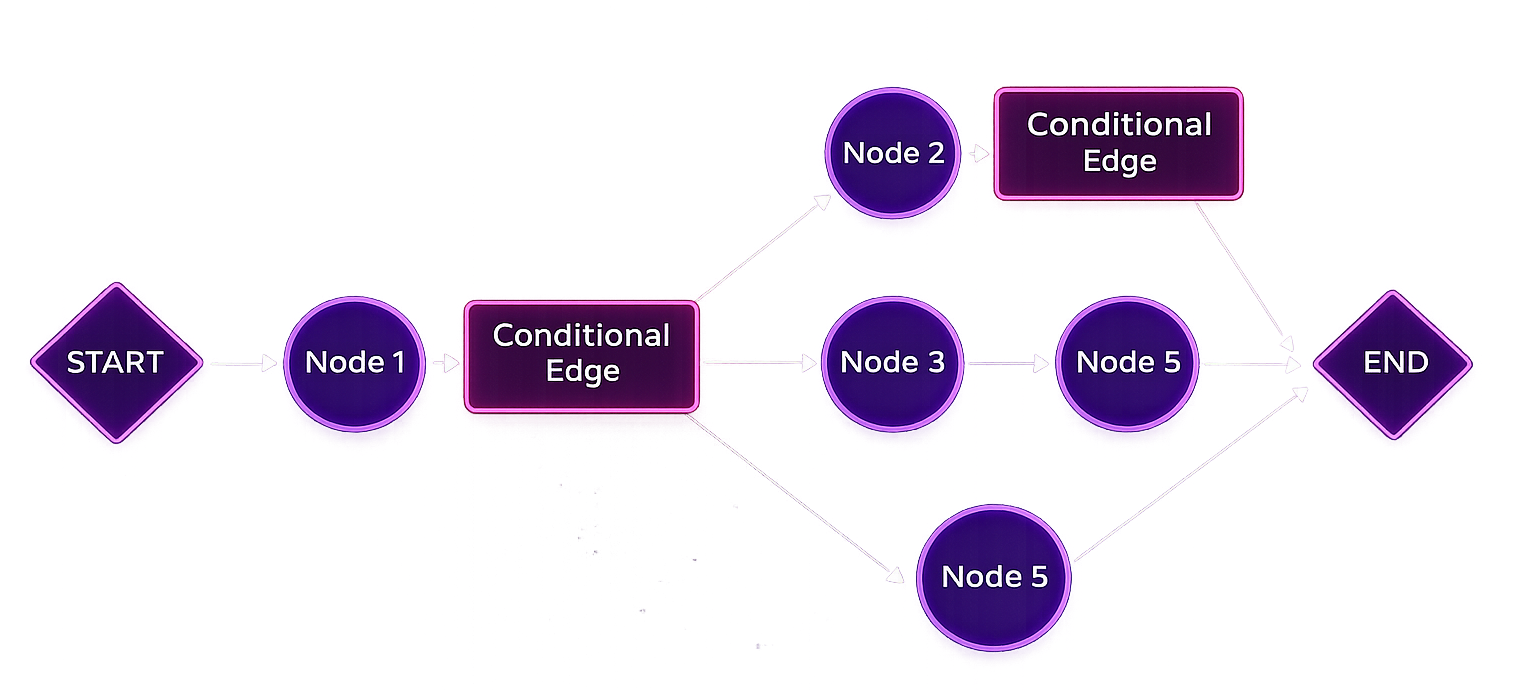
Autonomous multi-agent workflows with LangChain and LangGraph orchestration, tool usage, and resilient execution.
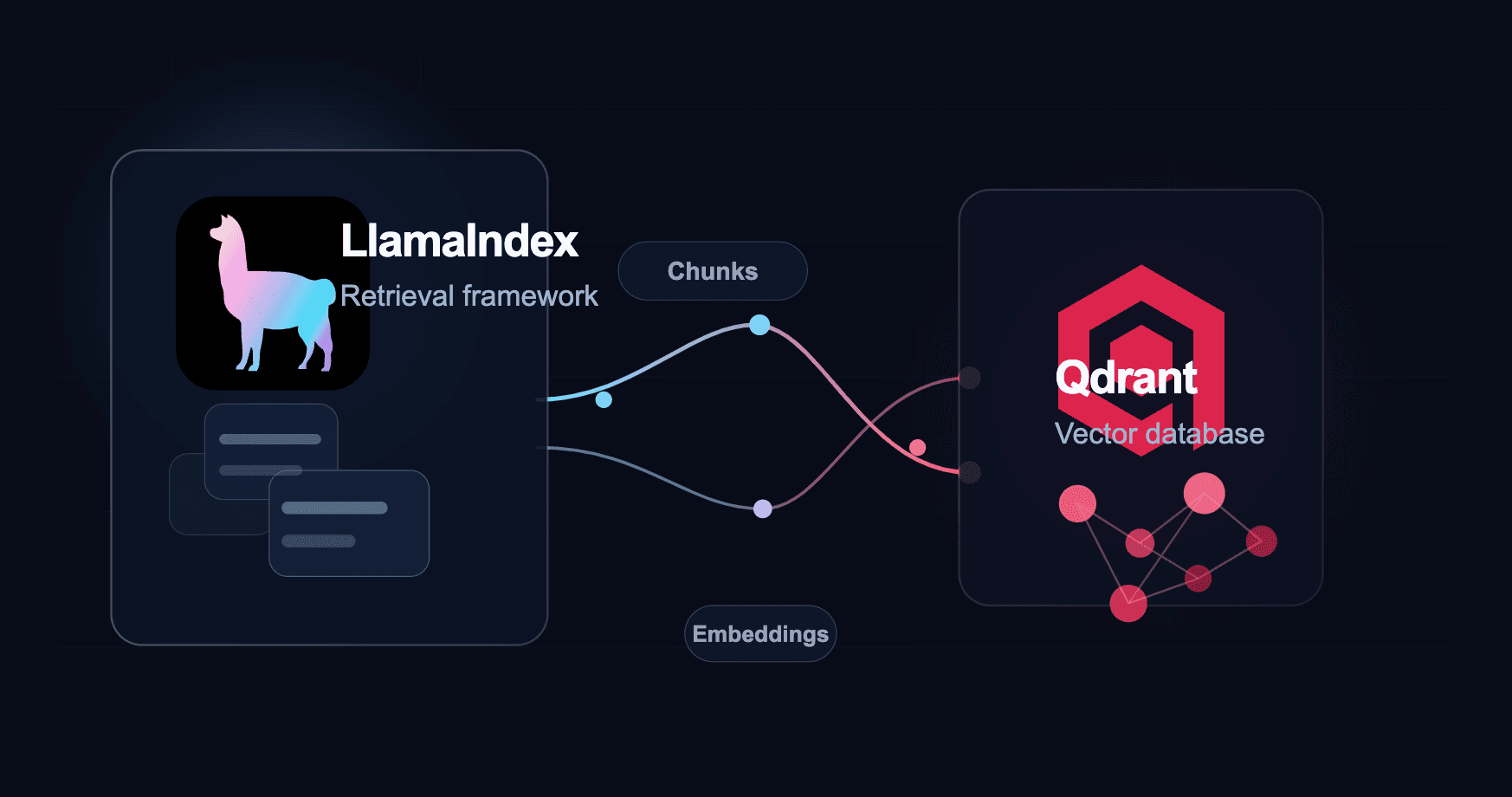
Production retrieval over internal knowledge with ingestion pipelines, hybrid search, and evals.

Production-ready AI backends with FastAPI, Docker, Cloud Run, auth, queues, and rate limiting.
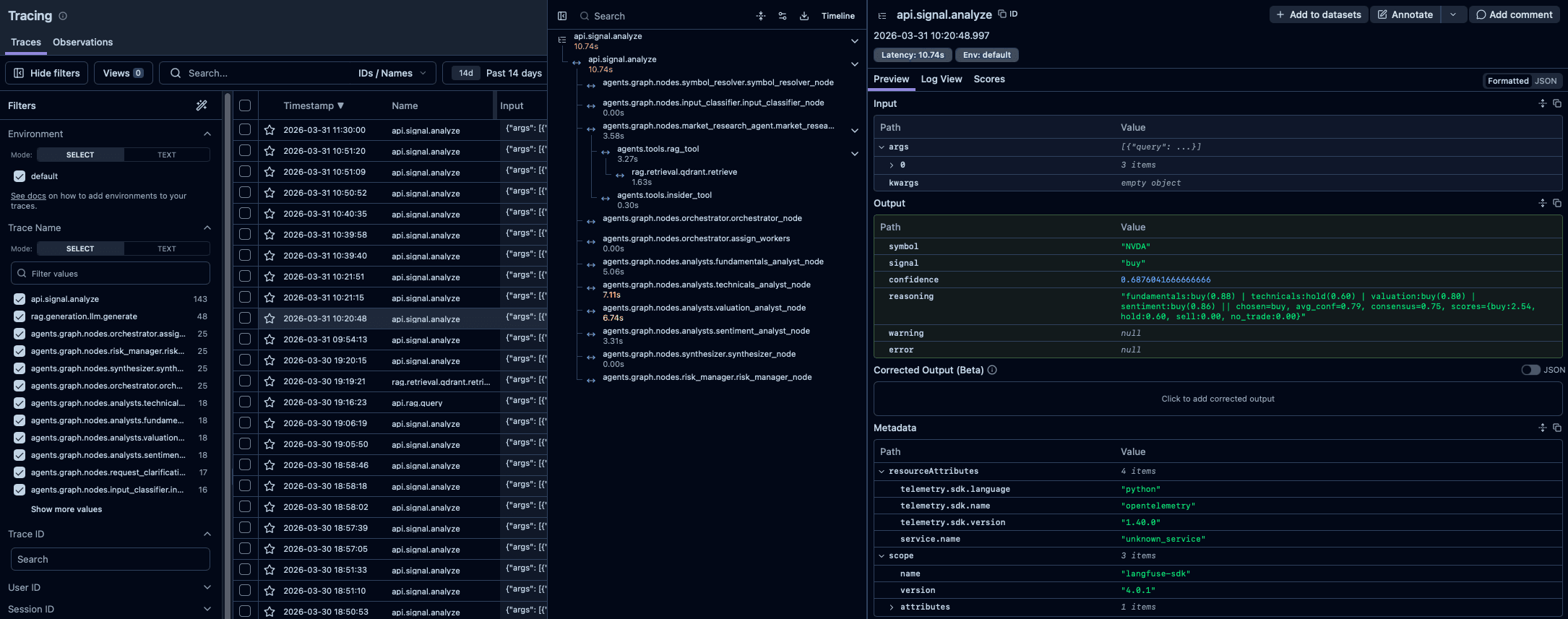
Tracing, quality metrics, and eval pipelines with Langfuse and DeepEval to continuously measure and improve AI system.

Unsloth-powered LoRA/QLoRA fine-tuning, evaluation, and high-throughput vLLM serving for efficient domain adaptation in production.
We built a multi-agent research workspace that combines market data retrieval, memo generation, and portfolio analysis so analysts can move from raw inputs to investment theses faster.
GitHubWe fine-tuned and evaluated a domain-specific memo model for financial reporting, then packaged it into a reliable inference pipeline for internal analyst workflows.
GitHubLangGraph
Agent orchestration and workflow routing
LlamaIndex
RAG indexing and retrieval pipelines
vLLM
High-throughput inference serving
Docker
Containerized build and deployment
Unsloth / HuggingFace
Fine-tuning workflows and model tooling
Langfuse
LLM observability, tracing, and analytics
Qdrant
Vector DB for semantic search
FastAPI
API layer for production deployment
GCP Cloud Run
Production deployment for AI backends
DeepEval
LLM evaluation and regression testing
